
Also posted to LessWrong.
Fair warning: this is mostly a null result. I tried to figure out what drives the capabilities spike using METR’s time horizon data, and didn’t find much signal. I’m sharing it because it seems good to share null results.
Key takeaways
- The “capabilities spike” refers to the observation that current AI agents are significantly stronger on some sorts of tasks than others.
- I analysed METR’s transcripts of AIs completing time horizon benchmark tasks to test various hypotheses for what causes the spike.
- I found little-to-no support for any of these hypotheses, but I think this is mostly because of limitations of my analysis framework and the dataset.
- Still, this is a moderate update for me that it’s hard to describe the current capabilities spike using simple, objectively measurable properties of tasks.
Context
This “capabilities spike” has been discussed extensively (e.g. here, here, here). Ryan Greenblatt has recently written that AI agents perform best on “easy-and-cheap-to-verify software engineering tasks that don’t require that much novel ideation” (ESNI). Meanwhile, METR recently speculated that AI agents perform better on MirrorCode than on Time Horizon 1.1 because MirrorCode tasks “provide a precise, checkable specification, and/or because AI companies are already training on similar tasks”.
I used data from METR’s time horizon benchmark to test various hypotheses.
Methodology
I performed an empirical analysis of how various factors correlate with task difficulty for AIs within METR’s time horizon benchmark tasks.
To measure the factors, I used GPT-5.4 to grade METR’s HCAST and RE-Bench tasks1. For each task, I placed GPT-5.4 inside the task environment and asked it to score the task on around 25 binary factors that might be important for task difficulty (see Appendix: factors for the factors, and Appendix: full prompt for the full rubric). Factors included “close to training distribution”, “cheaply check exact score”, and an operationalisation of Ryan Greenblatt’s “ESNI”.
I quantified “task difficulty for AIs” as how much AIs’ average success rate deviated from the success rate predicted by the time horizon fit. More precisely, for each task–model pair \((t, m)\) I computed the residual
\[\delta_{t,m} \;=\; p^{\text{actual}}_{t,m} - p^{\text{pred}}_{t,m}\]where \(p^{\text{actual}}_{t,m}\) is the model’s mean success rate on the task, and \(p^{\text{pred}}_{t,m}\) is the success rate predicted by that model’s fitted time-horizon curve.2
I then averaged \(\delta_{t,m}\) across four target models: Claude Opus 4.5, Claude Opus 4.6, GPT-5.2, and GPT-5.3-Codex.
I iterated on the factors, grader prompt, and factor performance metrics using a small subset of the tasks, before running the analysis on the full set.
The analysis code can be found here.
Results
Unfortunately, from my initial results, this approach looks unpromising.
The plot below shows how the three factors I pre-registered as most promising vary with task difficulty on three metrics: correlation, mean difference, and sign discrimination (see Appendix: metrics for definitions).
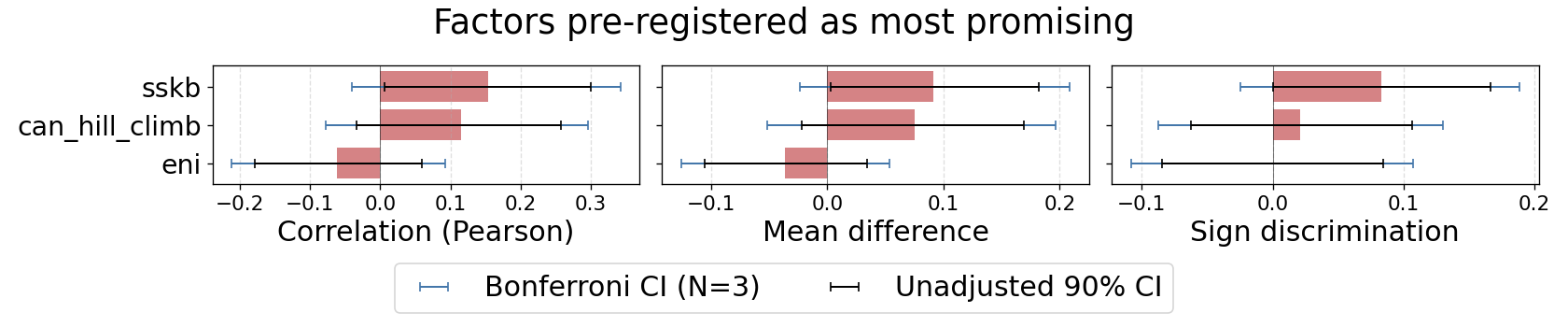
“SSKB” means “can hill climb by iteratively combining known approaches, or it’s so straightforward that hill climbing isn’t necessary”. “ENI” is an operationalisation of Ryan Greenblatt’s “ESNI” but without the “SWE” condition (see Appendix: factors for the full definitions).
The blue and black lines show bootstrapped confidence intervals (the wider blue ones include a Bonferroni adjustment – the unadjusted confidence intervals can’t establish significance because they don’t account for the fact that I’m testing multiple hypotheses here, one per factor). The effect sizes are small, and one of them points in the wrong direction. The confidence intervals3 are wide.
We might hope that other factors outside of my “most promising” list would do better. The plot below shows the same metrics for a wider set of factors, which I pre-registered as interesting to test (it includes the three factors shown above).
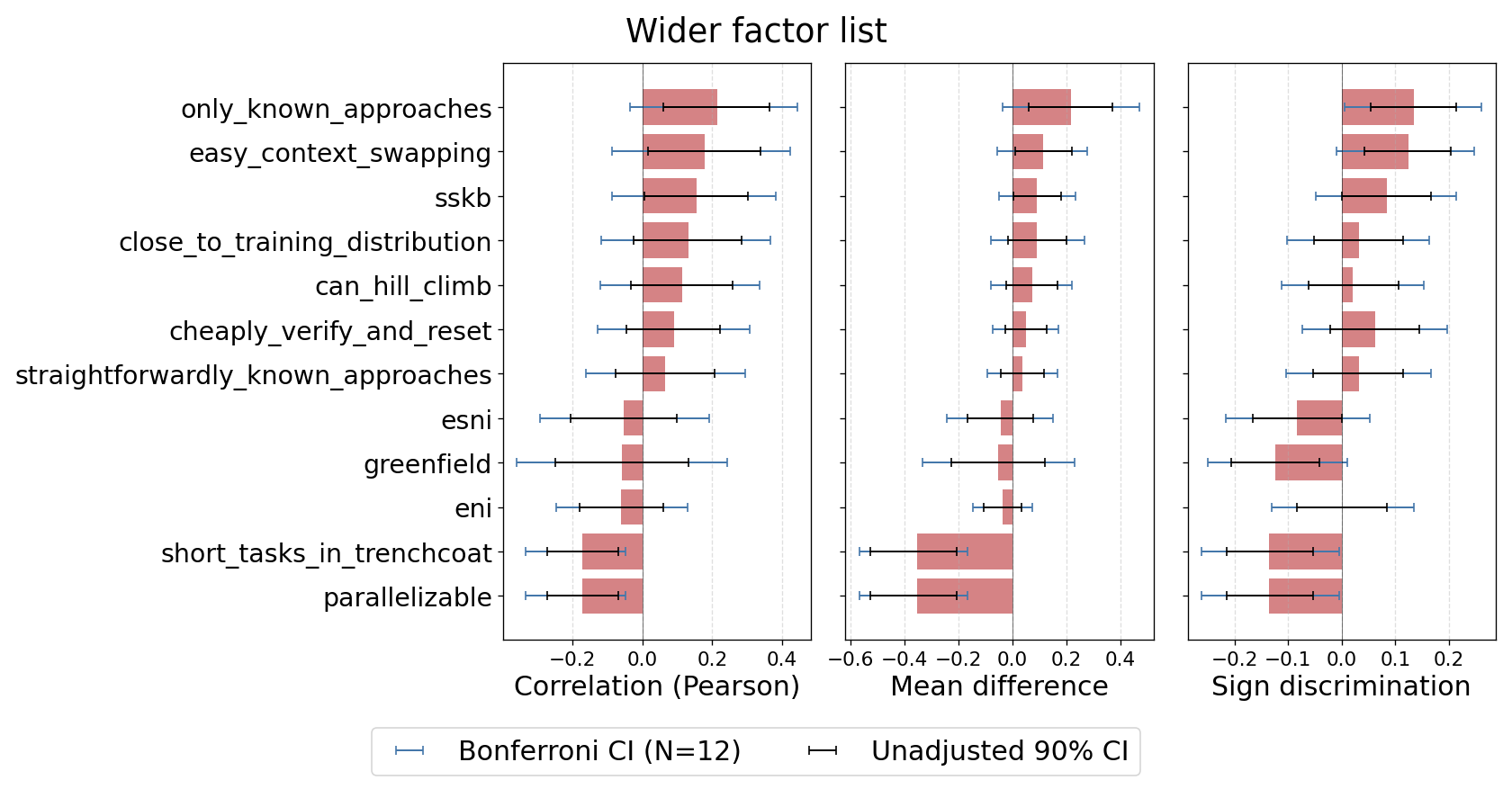
Again, we are not seeing significant results in the expected direction, except for only_known_approaches, which is just barely significant on one of the metrics.4
Why is there no clear signal?
To be clear, I continue to think that there is a capabilities spike, despite these results.
My top theories for what’s going on with my results:
- The spike might be significantly more noticeable outside of the time horizon task suite.
- This analysis only considers variations in tasks within the time horizon task suite, but that’s quite a restricted set of tasks: they are automatically gradable software tasks taken mostly from software engineering, machine learning, and cybersecurity.
- Having said this, I do think there really is a capabilities spike within the time horizon task suite, even if it’s less dramatic than the spike across all possible tasks.
- Maybe my analysis framework was critically flawed: I could have put significantly more effort into the framework (and this is harder to fix without introducing bias now that I’ve seen results on the full dataset).
- Maybe the factor definitions, grader rubric, or grader framework were too imperfect.
- The grader factor ratings seemed reasonable based on my spot checking, but my spot checking was quite limited and imperfect.
- I faced two issues when spot checking: 1) some factors are only vaguely specified; 2) I didn’t always have a detailed enough understanding of the tasks to make a confident judgement.
- Maybe spot checking more examples would have uncovered new problems with the rubric.
- The grader had the same access to the environment that an agent attempting the task for real would have. Giving the grader access to more task info might have helped. For example, golden solutions might have helped clarify how much novel thinking is required.
- The binary factors are often a significant simplification, and maybe I would have found more signal with scalar factors.
- The grader factor ratings seemed reasonable based on my spot checking, but my spot checking was quite limited and imperfect.
- Maybe I didn’t use a good measure for task-difficulty-for-AIs.
- However, switching to the Pearson residual didn’t meaningfully change the results.
- Maybe I didn’t include the most important factors.
- I think I did cover the theories that are currently most popular.
- Maybe I should have taken a different approach entirely.
- Maybe the factor definitions, grader rubric, or grader framework were too imperfect.
- Maybe imperfections in the task scores are obscuring the signal.
- When models cheat on the tasks, they score 0, but they might sometimes cheat on tasks they could solve correctly. This could obscure genuine relationships between factors and scores.
- The analysis is quite sensitive to task baselining, and task baselining is imperfect (e.g., tasks are baselined by human experts, but who counts as an expert?). Maybe improving baselining would cause a signal to emerge.
- Some tasks have specific potential issues. For example: some tasks rely on external resources like websites that change over time, meaning task difficulty can drift compared to when the human baselines were collected.
- The logistic fit might contribute to noise in the residuals. I don’t know of strong theoretical reasons to expect the relationship between log(human expert time) and AI success rate to be logistic. Alexander Barry’s analysis finds that the logistic performs at least as well as alternatives on cross-validation, which is somewhat reassuring, though he also finds that different reasonable fits produce substantially different time horizon estimates.
- Maybe reality is just kind of complicated.
- I think i) multiple factors are important, and ii) they correlate with each other in complicated ways. I think the capabilities spike is genuinely complicated to describe and explain.
My take on the capabilities spike
Here I’ll share my speculative take on the capabilities spike from my experience looking at transcripts and model performance on METR’s time horizon benchmark.
My best guess is that spikiness within software tasks like those found in METR’s time horizon benchmark5 is explained by:
- Closeness to training distribution
- Prior knowledge (at a high level) of the approaches needed to solve the problem should help a lot.
- Knowing the implementation details should help even more.
- Hill climbability
- Hill climbable tasks are probably very well represented in training data, but I think they’re also inherently easier for models.
- But I think hill climbability isn’t necessary if the problem is rote.
I think both of the above are strongly connected to models struggling with creativity / novel ideation / coming up with novel approaches to solve a problem. Possibly, this could be pulled out as a separate additional factor.
Acknowledgements
Many thanks to METR for providing resources for this project, including task data and software infrastructure. Particular thanks to Lucas Sato and Alexander Barry. All mistakes are my own.
Appendix
Appendix: factors
| Factor | Description |
|---|---|
| exact_score_tool | 1 if the agent has a score() tool, or is provided a scoring script it can run, which the agent can use to check its exact score cheaply and without limit. 0 if it knows the scoring function but must self-compute. 0 if the score() tool computes the score but doesn’t show it to the agent. |
| cheaply_check_exact_score | 1 if an agent can check its exact score cheaply and without limit. 0 if number of checks is limited, or if can only check a rough proxy. A score() tool that returns the actual score without limit counts as 1. Unlike exact_score_tool, being able to reproduce the scoring function locally also counts as 1. |
| cheaply_check_reasonable_proxy | 1 if the agent can check at least a good proxy of its score (as a scalar) — either via exact scoring, a provided tool, or by constructing its own scoring framework (e.g. creating a validation set and running its solution on that). 0 if the agent can only compute pass/fail (though note that a test suite with multiple tests counts as scalar scoring — the fraction of tests passing is a useful scalar proxy even if the official task score is binary). 0 if the agent has essentially no way to estimate its score before submitting. 0 if number of checks is limited. |
| cheaply_verify_known_threshold | 1 if the agent can reliably determine whether its current solution passes or fails before submitting, including by self-computing the scoring function (and knowing the pass threshold) or by running all provided tests and seeing them pass. |
| cheaply_verify_guess_threshold | 1 if the agent can reliably determine how well its solution is scoring before submitting, including by self-computing the scoring function or by running the provided tests. It’s fine if the agent doesn’t know the exact pass threshold, provided that it’s clear it should be aiming for as good a score as possible. Unlike cheaply_check_exact_score, a binary pass/fail is fine. As with cheaply_check_exact_score, the number of checks should be unlimited. |
| diagnostic_feedback | 1 if the agent gets useful feedback during execution beyond just a scalar score — e.g. test results, error messages, compiler output, intermediate metrics that indicate progress. 0 if the agent can score itself, but it just gets a numerical score with no further feedback. |
| cheaply_reset | 1 if there are no states the agent can reach that are hard to recover from (e.g. because the agent has access to a finite number of queries against a validation endpoint). 0 if mistakes can be costly/irreversible. |
| no_backtracking | 1 if it’s unlikely the agent will need to discard a partially working solution because a fundamentally different approach is needed. 0 if local optima or dead-end approaches are at least somewhat likely to be encountered. |
| granular_scoring | 1 if the scoring is granular enough that the agent can iteratively improve its score in small increments. 0 if scoring is too coarse for meaningful hill climbing (e.g. binary pass/fail with no partial credit, or a small number of discrete score levels). |
| has_internet_access | 1 iff the agent has internet access for online research. |
| close_to_training_distribution | 1 if the task is likely in the same reference class as tasks a frontier AI model was trained/RL’d on (e.g. standard coding, ML engineering, data analysis, debugging). 0 if the task requires unusual skills or domain knowledge not well-represented in training. |
| swe | 1 if the task is more or less a pure software engineering task (writing code, debugging, implementing a system). 0 if another discipline is an important component — including ML engineering, cybersecurity, data collection, scientific reasoning, math research, logic puzzle, etc. |
| only_known_approaches | 1 if the agent can solve the task just by iteratively combining approaches/strategies known to it through training data or provided context. The implementation steps of each approach must be known (at least approximately) — it’s not enough to just have a general awareness that the approach exists. 0 if the task requires formulating new approaches, or figuring out somewhat tricky implementation details, or combining known approaches in a complex way that’s hard to reasonably discover by trial and error. |
| straightforwardly_known_approaches | 1 if the task can be solved by rote execution of a simple combination of well-known approaches (either from training data or the task environment) without adaptation or creativity. This is significantly stricter than only_known_approaches — this means the solution path is obvious and well-trodden. |
| no_novel_ideation | 1 if the agent can solve the task using ideas that are either already on the internet, or provided context (e.g. papers on disk). 0 if the task must be solved by genuinely novel ideas. |
| easy_credit_attribution | 1 if it’s clear that success will be down to the agent’s own skills. 0 if the agent can sometimes succeed (or fail) purely by luck, or if it can only partially influence success/failure at the task. |
| short_tasks_in_trenchcoat | 1 iff the task can be decomposed into subtasks such that the longest subtask takes <5% as long for a human expert as the overall task. 0 if there’s at least one subtask that dominates the difficulty. |
| parallelizable | 1 iff a team of human experts could complete the task in <10% of the time it would take 1 human expert. |
| greenfield | 1 if the task involves creating a significant artifact from scratch, with a range of different approaches/architectures/structures possible, and the agent being free to choose between these. 0 if the task is more constrained (fill in a template, fix existing code, answer a question). |
| easy_context_swapping | 1 if expert humans taking X hours on average could complete the task by swapping in/out experts who are each allowed only X/10 hours. 0 if the task requires deep sustained context that makes handoffs costly. |
| can_hill_climb | 1 if ALL of: cheaply_check_reasonable_proxy=1 AND no_backtracking=1 AND granular_scoring=1. |
| eni | 1 if ALL of: cheaply_check_reasonable_proxy=1 and no_novel_ideation=1. |
| esni | 1 if ALL of: eni=1, swe=1. |
| skb | 1 if ALL of: can_hill_climb=1 and only_known_approaches=1. |
| sskb | 1 if either skb=1, OR straightforwardly_known_approaches=1. |
| cheaply_verify_and_reset | 1 if cheaply_verify_known_threshold=1 AND cheaply_reset=1. |
Appendix: full prompt
You are a task grader. You will evaluate an AI agent task by exploring the task environment and grading it on specific factors. You are inside the task environment and can use tools to explore files, run commands, read scoring code (if provided), and examine the setup. You're provided with exactly the same tools the agent would have when solving the task.
For the avoidance of doubt: since you are grading the task (not solving it), you should ignore any submission instructions in the task (e.g. "submit the empty string") — your submission should contain your factor grades as JSON as described below.
## Your process
1. Read the task instructions provided below.
2. Explore the environment to understand:
- What scoring function is used (look for a `score` tool, scoring scripts, test suites, or analytic functions in the task description -- sometimes there won't be any, that's fine)
- What other tools, data, and resources are available
- What the task structure looks like (greenfield vs constrained, parallelizable vs sequential, etc.)
3. Grade each factor below with a brief explanation. Most factors are binary (0 or 1). Three factors use other scales: creativity_required (1-10), team_time_pct (1-100), and task_difficulty_for_ais (-10 to 10).
## Factor definitions
Grade the task on each factor
**Scoring factors:**
1. **exact_score_tool**: 1 if the agent has a `score()` tool, or is provided a scoring script it can run, which the agent can use to check its exact score cheaply and without limit. 0 if it knows the scoring function but must self-compute. 0 if the `score()` tool computes the score but doesn't show it to the agent.
2. **cheaply_check_exact_score**: 1 if an agent can check its exact score cheaply and without limit. 0 if number of checks is limited, or if can only check a rough proxy. A `score()` tool that returns the actual score without limit counts as 1. Unlike exact_score_tool, being able to reproduce the scoring function locally also counts as 1.
3. **cheaply_check_reasonable_proxy**: 1 if the agent can check at least a good proxy of its score (as a scalar) — either via exact scoring, a provided tool, or by constructing its own scoring framework (e.g. creating a validation set and running its solution on that). 0 if the agent can only compute pass/fail (though note that a test suite with multiple tests counts as scalar scoring — the fraction of tests passing is a useful scalar proxy even if the official task score is binary). 0 if the agent has essentially no way to estimate its score before submitting. 0 if number of checks is limited.
4. **cheaply_verify_known_threshold**: 1 if the agent can reliably determine whether its current solution passes or fails before submitting, including by self-computing the scoring function (and knowing the pass threshold) or by running all provided tests and seeing them pass.
5. **cheaply_verify_guess_threshold**: 1 if the agent can reliably determine how well its solution is scoring before submitting, including by self-computing the scoring function or by running the provided tests. It's fine if the agent doesn't know the exact pass threshold, provided that it's clear it should be aiming for as good a score as possible. Unlike cheaply_check_exact_score, a binary pass/fail is fine. As with cheaply_check_exact_score, the number of checks should be unlimited.
**Feedback and iteration factors:**
6. **diagnostic_feedback**: 1 if the agent gets useful feedback during execution beyond just a scalar score — e.g. test results, error messages, compiler output, intermediate metrics that indicate progress. 0 if the agent can score itself, but it just gets a numerical score with no further feedback.
7. **cheaply_reset**: 1 if there are no states the agent can reach that are hard to recover from (e.g. because the agent has access to a finite number of queries against a validation endpoint). 0 if mistakes can be costly/irreversible.
8. **no_backtracking**: 1 if it's unlikely the agent will need to discard a partially working solution because a fundamentally different approach is needed. 0 if local optima or dead-end approaches are at least somewhat likely to be encountered.
9. **granular_scoring**: 1 if the scoring is granular enough that the agent can iteratively improve its score in small increments. 0 if scoring is too coarse for meaningful hill climbing (e.g. binary pass/fail with no partial credit, or a small number of discrete score levels).
**Task nature factors:**
10. **has_internet_access**: 1 iff the agent has internet access for online research.
11. **close_to_training_distribution**: 1 if the task is likely in the same reference class as tasks a frontier AI model was trained/RL'd on (e.g. standard coding, ML engineering, data analysis, debugging). 0 if the task requires unusual skills or domain knowledge not well-represented in training.
12. **swe**: 1 if the task is more or less a pure software engineering task (writing code, debugging, implementing a system). 0 if another discipline is an important component -- including ML engineering, cybersecurity, data collection, scientific reasoning, math research, logic puzzle, etc. For example, a task would be scored 0 if it involves substantial mathematical reasoning, even if a significant proportion of the work is software engineering.
13. **only_known_approaches**: 1 if the agent can solve the task just by iteratively combining approaches/strategies known to it through training data or provided context (e.g. papers on disk, or through online search if has_internet_access). The implementation steps of each approach must be known (at least approximately) -- it's not enough to just have a general awareness that the approach exists. 0 if the task requires formulating new approaches, or figuring out somewhat tricky implementation details, or combining known approaches in a complex way that's hard to reasonably discover by trial and error.
14. **straightforwardly_known_approaches**: 1 if the task can be solved by rote execution of a simple combination of well-known approaches (either from training data or the task environment) without adaptation or creativity. This is significantly stricter than only_known_approaches -- this means the solution path is obvious and well-trodden.
15. **no_novel_ideation**: 1 if the agent can solve the task using ideas that are either already on the internet, or provided context (e.g. papers on disk). 0 if the task must be solved by genuinely novel ideas.
16. **easy_credit_attribution**: 1 if it's clear that success will be down to the agent's own skills. 0 if the agent can sometimes succeed (or fail) purely by luck, or if it can only partially influence success/failure at the task.
**Task structure factors:**
17. **short_tasks_in_trenchcoat**: 1 iff the task can be decomposed into subtasks such that the longest subtask takes <5% as long for a human expert as the overall task. 0 if there's at least one subtask that dominates the difficulty.
18. **parallelizable**: 1 iff a team of human experts could complete the task in <10% of the time it would take 1 human expert.
19. **greenfield**: 1 if the task involves creating a significant artifact from scratch, with a range of different approaches/architectures/structures possible, and the agent being free to choose between these. 0 if the task is more constrained (fill in a template, fix existing code, answer a question).
20. **easy_context_swapping**: 1 if expert humans taking X hours on average could complete the task by swapping in/out experts who are each allowed only X/10 hours. 0 if the task requires deep sustained context that makes handoffs costly (e.g. maintaining a complex mental model across many interdependent steps).
**Scalar factors (not binary):**
21. **creativity_required**: How much creative problem-solving, novel hypothesis generation, or non-obvious ideation does the task require? Score 1-10 where 1 = purely mechanical execution (follow explicit instructions step by step) and 10 = requires fundamentally new ideas that don't exist in any known literature or training data. Middle scores: 3 = standard techniques with minor adaptation, 5 = known techniques but non-obvious how to combine or apply them, 7 = requires significant insight or creative leaps beyond textbook approaches.
22. **team_time_pct**: Score 1-100. What percentage of solo expert time would a team of human experts need? E.g. if one expert takes 10 hours and a team could do it in 2 hours, score is 20. Lower = more parallelizable. Give an integer, no % symbol.
23. **task_difficulty_for_ais**: How much harder is this task for AIs than for humans, on a scale -10 to 10? -10: this task is dramatically easy for AIs; humans find it hard but AIs find it very easy. -5: this task is significantly easier for AIs, AIs have a strong edge over humans. -3: this task is noticeably easier for AIs, AIs are somewhat more well-suited to this task compared to humans. 0: AIs and humans find this task about equally difficult. The +ve scores are analogous to the -ve ones, with "humans" and "AIs" swapped.
**Composite factors (entirely derived from earlier factors):**
24. **can_hill_climb**: 1 if ALL of: cheaply_check_reasonable_proxy=1 AND no_backtracking=1 AND granular_scoring=1.
25. **eni**: 1 if ALL of: cheaply_check_reasonable_proxy=1 and no_novel_ideation=1.
26. **esni**: 1 if ALL of: eni=1, swe=1.
27. **skb**: 1 if ALL of: can_hill_climb=1 and only_known_approaches=1.
28. **sskb**: 1 if either skb=1, OR straightforwardly_known_approaches=1.
29. **cheaply_verify_and_reset**: 1 if cheaply_verify_known_threshold=1 AND cheaply_reset=1.
## Output format
When you are done exploring, submit a JSON object with each factor as a key. Each factor should have:
- "score" (0 or 1 for binary factors; 1-10 for creativity_required; 1-100 for team_time_pct; -10 to 10 for task_difficulty_for_ais)
- "confidence" (1-10, how confident you are in your score)
- "explanation" (brief reasoning with evidence from what you found in the environment)
- "uncertainty" (what makes you unsure, or "none")
Finally, include a top-level "process_feedback" key in your JSON with your thoughts on the grading process itself — what was confusing, what factor definitions were ambiguous, and how the rubric or process could be improved.
The task to grade is below. There are a lot of factors, so when you are ready to submit, output your draft answers, and then *do a final check of your answers against the grading criteria*. Revise as necessary. When you're happy that your answers accurately reflect the criteria, you should submit.
Appendix: metrics
I scored each factor on three metrics. For all three, positive values mean the factor predicts AI finding the task easier (negative residual), and negative values mean it predicts AI finding the task harder. All confidence intervals are 95% bootstrap CIs computed from shared resamples across the three metrics.
Pearson correlation. Negative Pearson \(r\) between the binary factor value \(x\) and the continuous residual \(y\) (negated because positive residual = AI finds it harder, so negating aligns with the “positive = easier” convention).
Mean difference. \(\bar{y}_{x=0} - \bar{y}_{x=1}\): the difference in mean residual between tasks where the factor is absent (\(x = 0\)) and tasks where it is present (\(x = 1\)). A positive value means tasks with the factor have lower residuals (easier for AI) on average.
Sign discrimination. On the subset of tasks with \(\lvert y \rvert > 0.1\) (I use this subset to exclude near-zero residuals), this metric measures how well the factor predicts the sign of the residual: \(\text{mean}(x = \mathbb{1}[y < 0]) - 0.5\). The range is \([-0.5, +0.5]\), where \(0\) is chance, and \(+0.5\) means \(x = 1\) perfectly predicts negative residual (AI finds it easier).
Notes
-
METR’s time horizon benchmark is composed of HCAST, RE-Bench, and a set of shorter novel software tasks – I excluded the set of shorter novel software tasks because these tasks are usually trivial for recent AIs. ↩
-
Specifically, \(p^{\text{pred}}_{t,m} = \sigma\!\left(\beta_m \log_2 h_t + \alpha_m\right)\) where \(h_t\) is the task’s baseline human completion time, \(\sigma\) is the logistic function, and \(\alpha_m\) and \(\beta_m\) are fitted parameters from the logistic regression. ↩
-
I’m plotting 90% confidence intervals for α=0.05 significance testing because I am opinionated about the direction of the effect of the factors. Under this framework, the null is rejected if the lower end of the (Bonferroni-adjusted) 90% confidence interval exceeds 0. ↩
-
The Bonferroni adjustment is quite harsh because i) I’m testing a lot of factors here, and ii) Bonferroni doesn’t account for correlations between factors, so I don’t want to lean too much on the Bonferroni-adjusted results. But even without the Bonferroni adjustment, few factors are significant (especially if we exclude factors that are significant in the opposite direction to what we expected). ↩
-
I’ll keep my speculation restricted to variation within software tasks like those found in METR’s time horizon benchmark because I’m most familiar with these tasks. ↩